AIITK:: Text Generation Voice Transcription Text-To-Speech Image Generation
Text-To-Speech
A Text-To-Speech service is designed to convert text into spoken words. This is particularly useful for creating realistic voiceovers or spoken content from generated text from LLMs. AIITK provides access to two services for voice generation, OpenAITTS and ElevenLabs. AIITK's TTS functions can also be used for automating the generation of pre-made voice lines or manipulating the raw audio data for communication with
OpenAITTS Parameters
- OpenAITTSParams
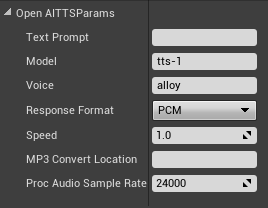
- Text Prompt: The input text for the text-to-speech conversion.
- Model: The specific text-to-speech model being used.
- Voice: The selected voice for the text-to-speech output.
- Response Format: The audio format for the output file (e.g., PCM or MP3).
- Speed: The playback speed of the generated audio.
- MP3 Convert Location: The directory where the MP3 converted files will be stored.
- Proc Audio Sample Rate: The sample rate of the processed audio in Hz.
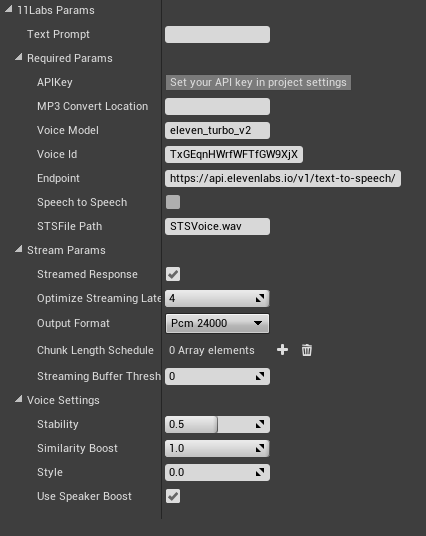
ElevenLabs Parameters
- ElevenLabsParams
- 11LabsRequiredParams
- APIKey: Your unique API key for accessing the service
- FileName: Disk location followed by file name for converting MP3 data to WAV for use in UE
- VoiceModel: Identifier for the voice model to be used
- VoiceId: Unique identifier for the specific voice
- Endpoint: Endpoint URL for the text-to-speech API
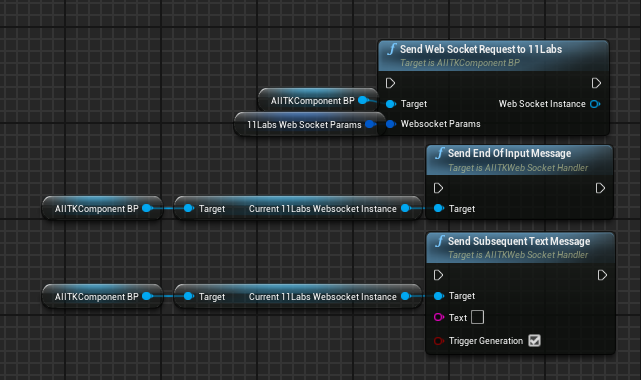
- SpeechToSpeech: Unreleased SpeechToSpeech generation alternative to TextToSpeech (EXPERIMENTAL)
- STSFilePath: Path of the file to be used for speech to speech requests (EXPERIMENTAL)
- 11LabsStreamParams
- bStreamedResponse: Enables or disables streaming of responses
- OptimizeStreamingLatency: Configures latency optimizations, affecting audio quality
- OutputFormat: Select the audio output format
- ChunkLengthSchedule: Determines how text is chunked for processing (WEBSOCKET REQUEST ONLY)
- StreamingBufferThreshold: Set to a factor of 2 to wait for the buffer of that size to fill before queuing the audio (WEBSOCKET REQUEST ONLY)
- 11LabsRequestParams
- TextPrompt: Text prompt for the voice generation
- RequiredParams: Required parameters for the request
- StreamParams: Parameters for stream handling
- VoiceSettings: Settings for voice modulation
- 11LabsVoiceSettings
- Stability: Adjusts the stability of voice generation, affecting the predictability and variability of output
- SimilarityBoost: Increases the likelihood of generating a voice similar to the target voice
- Style: Defines the stylistic aspects of voice generation, specific to V2+ models
- UseSpeakerBoost: Determines whether to enhance the speaker's distinct characteristics in the generated voice
- 11LabsRequiredParams
Voice Generation
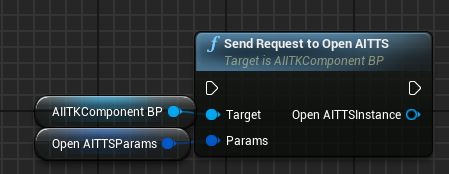
SendRequestToOpenAITTS
The SendRequestToOpenAITTS function takes a given text prompt and returns a sound wave that can be played in Unreal Engine. Raw audio data is also provided for saving generated voice directly to the disk or fed into audio utility functions for conversion/resampling/etc.
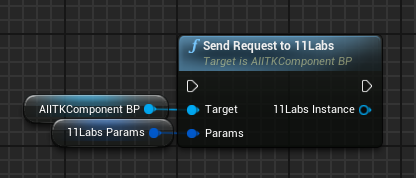
SendRequestToElevenLabs
The SendRequestToElevenLabs function takes a given text prompt and returns a sound wave that can be played in Unreal Engine. Raw audio data is also provided for saving generated voice directly to the disk or fed into audio utility functions for conversion/resampling/etc. (Huh... Deja Vu...)
Handling TTS Responses
These are the events available to you when utilizing the AIITKComponentBP component (Otherwise you will have to bind to the response events manually).
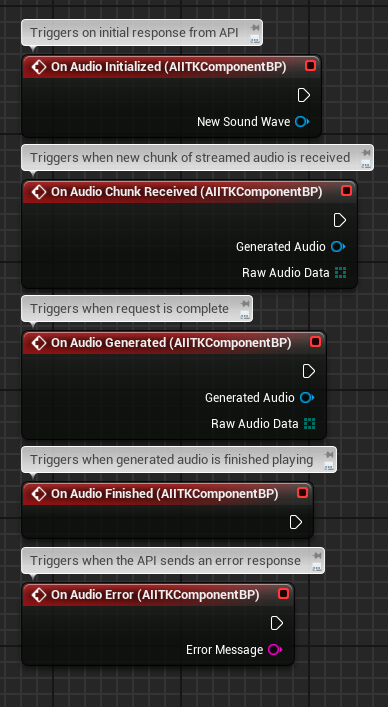
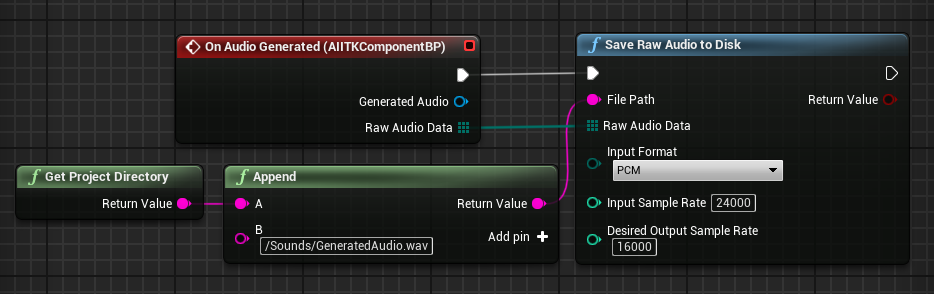
On the response events a USoundWave (USoundWaveProcedural for streamed audio) as well as the raw bytes in a uint8 TArray. This can be plugged into the AIITK Audio Processing Library utility functions for saving and conversion.
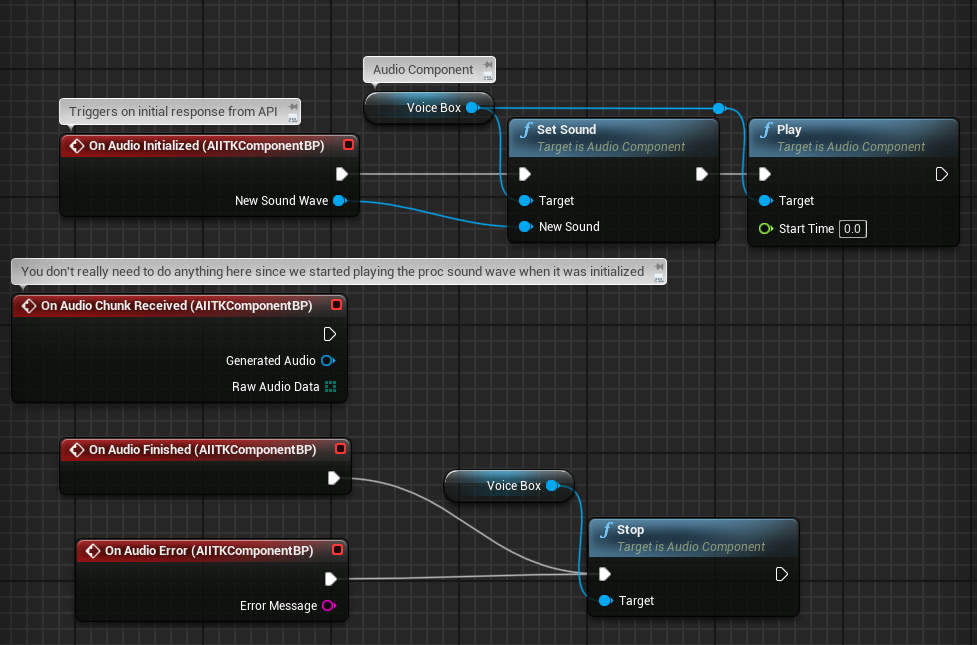
For consistency in a streamed response, assign the proc sound wave to an audio component and start playing on initialization so that it's ready for the audio stream. Stop the proc sound wave when the buffer is empty (OnAudioFinished) or if there is an error. Not required because it should be garbage collected eventually but recommended for controlling memory allocation/usage.
Experimental Features
11Labs Websocket Streaming, and Speech to Speech functionality is currently experimental. Speech to Speech doesn't have any documentation released yet. (Well, it was, but then they removed it? I had most of it complete before it was taken away and never spoken about again, weird, it's there for you to try anyway), and the Websocket endpoint is not reliable enough for a consistent audio stream.